[1] Gholamiandehkordi, A.R., Timbermont, L., Lanckriet, A., Van Den Broeck, W., Pedersen, K., Dewulf, J.,et al.(2007). Quantification of gut lesions in a subclinical necrotic enteritis model.Avian Pathology, 36, 375382.

25 May 2021
Comprensión de estudios que clasifican variables binarias: estudio con coccidiostáticos y enteritis necrótica
Cuando un nuevo artículo divulgativo o científico llega a nuestras manos, actualmente más bien a nuestra pantalla, deberíamos en pocos […]
Cuando un nuevo artículo divulgativo o científico llega a nuestras manos, actualmente más bien a nuestra pantalla, deberíamos en pocos minutos saber si es de nuestro interés o no. Leyendo el título y el resumen, ya nos da una idea de qué es lo que los autores han hecho, cómo lo han hecho y los resultados que han obtenido.
En este artículo queremos ayudar a los lectores a entender qué han hecho sus autores, cómo lo han hecho y cuáles han sido sus resultados en el artículo “The effect of commonly used anticoccidials and antibiotics in a subclinical necrotic enteritis model” de Lanckriet, A. et al., publicado en 2010. No vamos a entrar en los detalles científicos del artículo, sino que intentaremos ayudar al lector a visualizar qué se hizo y cómo se hizo para luego entender las conclusiones a las que llegaron los autores.
En resumen, los autores nos indican que la enteritis necrótica representa un riesgo en la producción de los pollos de engorde y realizaron un estudio dividido en dos partes con el objetivo de determinar el efecto profiláctico de varios productos anticoccidiósicos ionóforos de uso habitual sobre la incidencia de enteritis necrótica en un modelo de infección experimental subclínica utilizando la coccidia como factor predisponente. Además, estudiaron también si el tratamiento en el agua con antibióticos como tratamiento curativo en el mismo modelo experimental disminuía o no la enteritis necrótica. Los autores nos indican que su trabajo se basó principalmente en los trabajos de Gholamiandehkordi et al., en 2007[1] y en el de Timbermont et al., en 2008[2].
Antes de la fase experimental propiamente dicha, se realizó un estudio para conocer las concentraciones mínimas inhibitorias de los anticoccidiósicos y de los antibióticos usados como tratamiento frente a una serie de cepas de C. perfringens.


En ese artículo se realizaron dos estudios, uno con los anticoccidiósicos (estudio 1) y otro con los antibióticos (estudio 2).
En el estudio 1 se usaron 7 corrales que coinciden con los grupos experimentales, uno por grupo de tratamiento anticoccidiósico con 28 pollos de un día en cada uno. Así:
Estudio 1: anticoccidiósicos en el pienso suministrado ad libitum durante todo el ensayo:
Continua después de la publicidad.


- Grupo de Lasalocid a 75 ppm
- Grupo de Salimocina a 70 ppm
- Grupo de Maduramicina a 5 ppm
- Grupo de Narasin a 70 ppm
- Grupo de Narasin a 50 ppm junto con Nicarbazina a 50 ppm
- Grupo de pollos no medicado pero infectado
- Grupo de pollos no medicado ni infectado.
[2] Timbermont, L., Lanckriet, A., Gholamiandehkordi, A.R., Pasmans, F., Martel, A., Haesebrouck, F.,et al.(2008). Origin of Clostridium perfringensisolates determines the ability to induce necrotic enteritis in broilers. Comparative Immunology Microbiology and Infectious Diseases, 32, 503512.
Todos los pollos del estudio 1 excepto los del grupo 7 se infectaron con una cepa conocida de C. perfringens los días 17, 18, 19 y 20 del estudio de forma oral y además el día 18 se les administró a todos los pollos una sobredosis de 10 veces la dosis habitual de una vacuna frente a la coccidiosis.
Los día 22, 23 y 24, nueve pollos de cada grupo y día fueron eutanasiados realizándose un estudio de las puntuaciones frente a la enteritis necrótica de cada pollo según el método de Keyburn et al. en 2006[1]. Los pollos que tuvieron una puntuación de 2 (la escala va de 1 a 5) o superior fueron clasificados como positivos frente a enteritis necrótica.
Los datos fueron analizados con el programa SPSS en su versión 17.0 y se usó una regresión logística binaria para comparar el número de pollos positivos (puntuación >=2) entre los grupos de tratamiento (del 1 al 7) usando la corrección de Bonferroni para las comparaciones múltiples y determinaron que, al usar esta corrección, la significación estadística debería ser en el primer experimento de P<0,007 y en el segundo de P<0,0055.
Los autores ya destacan que esta significación estadística, al usar las comparaciones múltiples, sería el resultado de dividir la significación estadística habitual P<0,05 entre el número de grupos usados. Si realizamos la operación 0,05/7 (7 grupos usados en el primer estudio) obtendremos el valor 0,007 y si realizamos la operación 0,05/9 (9 grupos usados en el segundo estudio) obtendremos el valor 0,0055.
En la sección “Resultados” tenemos la tabla 2 donde se resume el número de pollos positivos a enteritis necrótica por día de estudio y grupo y su significación estadística. Para una mejor comprensión reproducimos a continuación los resultados de la prueba 1.
[1] Keyburn, A.L., Sheedy, S.A., Ford, M.E., Williamson, M.M., Awad, M.M., Rood, J.I. & Moore, R.J. (2006). Alpha-toxin of Clostridium perfringens is not an essential virulence factor in necrotic enteritis in chickens. Infection and Immunity, 74, 6496-6500

Tabla 1: Número de pollos con lesiones macroscópicas de enteritis necrótica (puntuación de “lesion” >=2) en cada día de muestreo.
Los autores nos informan de que algunos pollos murieron antes de realizar las eutanasias, pero sin lesiones de enteritis necróticas.
Lo primero que podemos observar es que el test de significación se realizó con todos los pollos ya eutanasiados. Esto lo observamos al ver que las indicaciones de significación estadística (los superíndices que indican los grupos de significación, en este caso la letra A) sólo se señalan en la columna de los totales. Esto implica que independientemente de cuándo un pollo fue sacrificado, solo se contemplan el número total de pollos con lesiones.
¿Cómo recogieron los datos los autores? Podemos imaginar la siguiente tabla que podemos construir nosotros mismos:
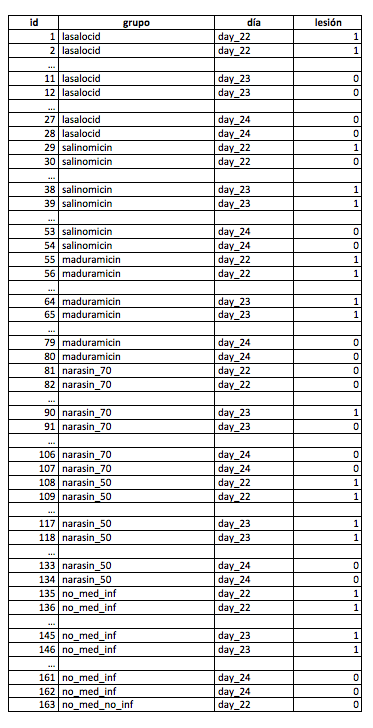
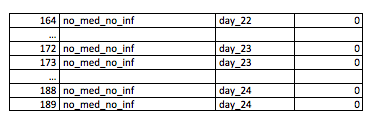
¿Qué hemos hecho?. Si vemos la tabla 1 de este artículo, se nos indica que el primer grupo de tratamiento, Lasalocid 75 ppm, tiene 4 pollos positivos de 28 eutanasiados. Hemos creado una tabla donde hemos creado la columna “id” como identificador de cada pollo, el grupo de tratamiento “grupo”, el día de eutanasia (aunque no lo necesitamos para el análisis, luego veremos por qué lo incorporamos) “día” y el campo “lesion” para indicar qué pollos fueron positivos.
Como en el primer grupo hay 4 pollos positivos, hemos dado valor 1 en la columna “lesión” a cada pollo en cada día de estudio. Volviendo a Lasalocid 75 ppm nos dice que hay 2 pollos positivos del día 22, 0 el día 23 y 2 el día 24 y así lo hemos creado. Y así sucesivamente con todos los grupos, días y pollos. Al final, si lo hacemos en Excel podemos crear varias tablas dinámicas que tendrán la siguiente forma para verificar nuestros datos:

Figura 1: Tabla dinámica con el número de pollos positivos
y que adjuntamos aquí:

Tabla 3: Número de pollos positivos por tratamiento
La tabla dinámica con el número total de pollos es la tabla 4:

Tabla 4: Número de pollos por tratamiento y día
Para realizar el análisis estadístico se usó una regresión logística binaria incorporando la corrección de Bonferroni para comparaciones múltiples que ya hemos explicado cómo se calcula.
La regresión logística es un tipo de análisis de regresión que se utiliza para predecir el resultado de una variable categórica en función de unas variables predictoras que pueden ser tanto categóricas como cuantitativas. Se utiliza para modelizar la probabilidad de un evento. Es parte de los modelos lineales generalizados (GLM en sus siglas en inglés) y usa la función de enlace logit.
Es un método de clasificación a la postre, que permite clasificar los sujetos y calcular las probabilidades de ocurrencia de un evento. En nuestro caso, la variable predictora independiente son los grupos de tratamiento y la variable predicha o dependiente es la variable “lesion” que permite clasificar los pollos en dos grupos: con lesión (Y = 1 o “lesion” = 1) o sin lesión (Y = 0 o “lesion” = 0). Por lo tanto, un modelo de regresión logística se comporta como un método de diagnóstico ya que la clasificación también produce falsos positivos y falsos negativos[1].
[1] Doménech, JM. (1996). Métodos estadísticos en ciencias de la salud. Unidad 13, pag 43
Aunque conocemos que las explicaciones matemáticas quedan fuera del alcance de este artículo no podemos obviar algunas de ellas. Así, las probabilidades (que pueden interpretarse como proporciones) de que haya pollos positivos para los diferentes grupos de tratamiento dibujan una curva en forma de “S” alargada. Esta curva es la que modeliza la función logística:

siendo “z” una combinación lineal de las variables independientes, en nuestro caso solamente la variable “grupo”, indicadora de la contribución del conjunto de los factores de riesgo. La función logística no da el valor de la respuesta, sino que estima la probabilidad p(x) de que un pollo tenga lesión (proporción que será utilizada para predecir si el pollo tiene o no lesión). La figura 2 muestra cómo sería esta función para un modelo típico.

Figura 2: Curva típica de la función logística
Así podemos realizar ahora con el archivo de datos generado un análisis de regresión logística y obtendremos las significaciones y resultados que los autores han obtenido. En su tabla de resultados, (la tabla 1 de este artículo), los autores sólo nos informan de que los grupos que tienen el superíndice “A” son estadísticamente diferentes cuando se comparan con el grupo de referencia citado, el grupo de pollos no tratado e infectado (en nuestra tabla aparece como “no_med_inf”) y no muestran las odds de lesión. El término odds es complicado para la cultura latina y fácil para la cultura anglosajona. Podemos interpretar una odds de 2 con el siguiente ejemplo: si el club A tiene una odds de 2 en sus enfrentamientos contra el club B, de cada 3 partidos jugados, 2 los ganará el A y 1 el B.
Es importante señalar que la regresión logística es ampliamente utilizada cuando se estudia el efecto de variables continuas (y también junto a categóricas) en la probabilidad de que se produzca un evento. En este caso, en el que la variable predictora es un solo factor, podría ser más adecuado hacer comparaciones múltiples de diferencias de proporciones. Este método nos llevaría a las mismas conclusiones, según hemos comprobado con el software estadístico y lenguaje de programación R (R Core Team (2021).